Since Walmart.com is unfortunately not one of our customers yet  we don’t have access to qualitative query performance data. But to test our hypothesis, we did a simple experiment with real-life users.
we don’t have access to qualitative query performance data. But to test our hypothesis, we did a simple experiment with real-life users.
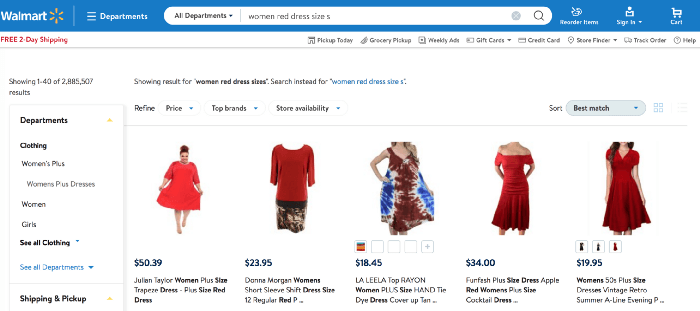
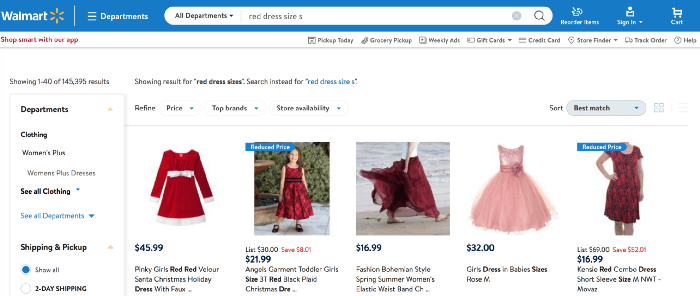
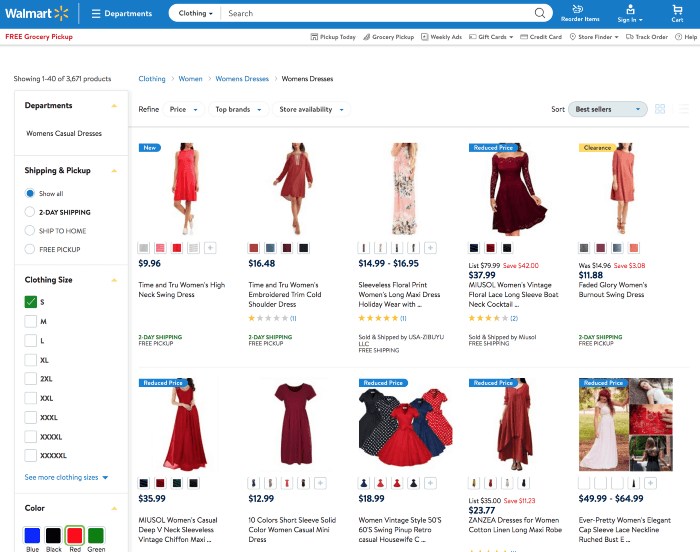
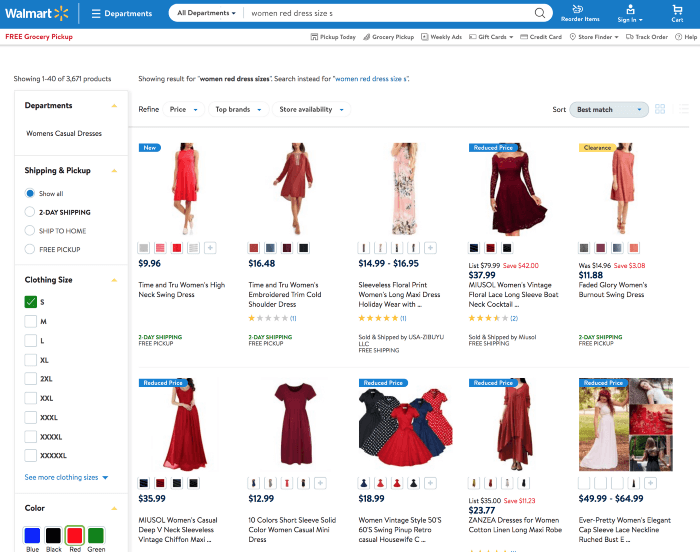
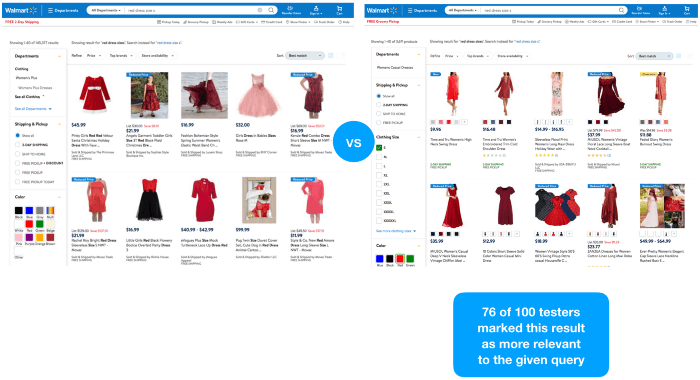
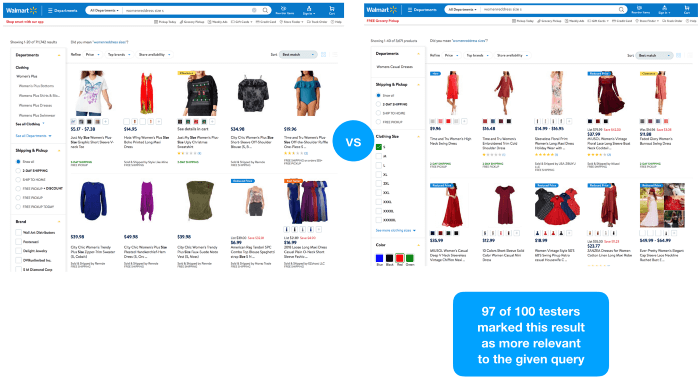
We used the faceted navigation result representing the intent of the given query “red dress size s” on walmart.com. We think that from a precision perspective, this would be the most relevant set of products Walmart could reply to the given query. Then we rebuild the page so that it matches perfectly a search results page in terms of look and feel.
1. In the first stage, we start by improving the user queries themselves.
Here we take advantage of our superior contextual query correction service which uses our concept of controlled precision reduction control. It automatically handles typos, misspellings, term decomposition, stemming and lemmatization at a yet unmatched level of accuracy and speed.
2. In the second stage, we try to understand the intent/meaning of the query
at this stage, the system tries to extract the entities and concepts mentioned in a query. As a result, search|hub predicts one or more possible intentions with a certain probability, which is particularly important for ambiguous queries.
Most other solutions that attempt to tackle the same problem are using predefined knowledge bases / ontologies to represent dependencies and invoking meaning into the system. We spend a lot of time evaluating existing models and decided to do it differently because we wanted to build a system that learns at scale (different domains), can solve the language gap between visitors and catalog domain experts (wording and language) and even more essential automatically reshapes / optimizes and adapts itself based on explicit and implicit feedback. Therefore, we have developed an automated entity relationship extraction and management solution based on reinforced learning. Another benefit of this solution is that it does not waste computation time and money on building knowledge we don’t need to have
3. Continuously test and learn which query/queries perform best for a given intent/meaning
Another big differentiator of search|hub is that it is entirely data-driven. For quite several queries, there is no single best intent / meaning. In these cases, the right intent / meaning might be dependent on context (time, region, etc.) Therefore, we automatically multivariate test ambiguous queries and query intentions.